웹 스크래핑과 웹 크롤링
크롤링(Crawling) 또는 스크래핑(Scraping)으로 혼동해서 쓰는 경우가 많이 있습니다.
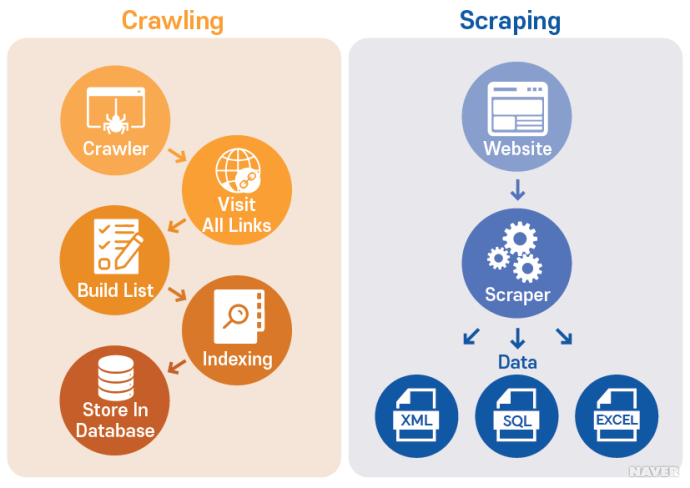
크롤링은 개인 혹은 단체에서 필요한 데이터가 있는 웹(Web)페이지의 구조를 분석하고 파악하여 긁어옵니다. 여기서 긁어온다는 의미는 모두 그대로 가져오는 것을 말합니다. 이것은 데이터를 추출한다로 설명할 수 있으며 크롤링이라는 행위를 하는 소프트웨어(혹은 프로그램)를 크롤러(Crawler)라고 부릅니다.

{kind=link}
[ Web Crawling과 Scraping의 차이]
4차 산업혁명이 시작되면서 사무업무 자동화(RPA, Robotic Process Automation)도 빠질 수 없게 되었습니다. 과거에는 육체노동과 단순 반복적인 작업을 자동화하였지만, 이제는 판단과 예측, 결정, 최적화와 같은 사람이 정신력을 소모해서 하는 행동들도 자동화하기 위해 발전하고 있습니다.
대표적으로 Python을 이용한 beautifulsoup과 selenium을 활용하여 머신러닝과 딥러닝의 데이터로 사용할 수 있는 텍스트화된 데이터를 만들 수 있으며 이를 통해 데이터 분석을 편하게 할 수 있게 되었습니다.
크롤링의 합법과 불법의 기준 알아보기
크롤링과 관련된 다음의 법조문을 읽어봅시다.
“정보통신망법 제48조 정보통신망 침해행위 금지”
누구든지 정당한 접근권한 없이 또는 허용된 접근권한을 넘어 정보통신망에 침입하여서는 아니된다
위 글을 읽어보면 기준이 어디서부터 어디까지인지 알기가 쉽지않으며 굉장히 애매모호합니다.

그래서…! 나름대로 제가 웹크롤링 및 스크랩핑을 진행하면서 얻었던 인사이트를 공유해드립니다.
수집한 데이터를 영리적인, 상업적인 용도로 활용할 때 주의해야합니다.
인터넷 브라우저 크롬 브라우저를 예로 “개발자 도구”라는 기능이 있습니다.
윈도우는 F12, 맥은 option+cmd+i 단축키를 사용하면 열립니다.

[ 개발자도구 사용방법 ]
앞으로 스크랩핑과 크롤링을 하려면 웹의 구조를 확인해야할 일이 많아지는데 개발자 도구를 통해 코드로 구성된 웹 페이지의 구조를 확인하실 수 있습니다.

[ 초록창에서 개발자도구 확인 ]
예를 들어봅시다. 여기에 있는 코드를 전부 긁어서 웹페이지를 클론코딩한 다음 상업적인 용도로 사용한다면 이것은 매우 심각한 문제를 야기할 수 있습니다.(초록창에서 법정 소송을?

)
스크랩핑 및 크롤링을 시도하면서 상대에게 피해를 입히지 않도록 주의해야합니다.
크롤링 및 스크랩핑을 하게 되면 일단 페이지를 왔다갔다 해야하는데 일련의 과정을 반복하게 되면 웹에서 크롤러라고 판단하여 서버를 차단하게 됩니다.
왜냐하면 우리의 눈에는 보이지않는 백엔드 영역에서는 서버로 많은 데이터와 패킷들이 지나다니고 있기 때문입니다. 페이지를 왔다갔다하면 데이터가 반복적으로 지나다니는 과정에서 서버가 과부하가 되고 펑하고 터져버립니다.(한명이 사용하는게 아닌 여러명이 다니는 길목이라 그렇습니다.) 이런 상황을 방지하기 위해 큰기업들은 여러가지 함정을 설치합니다.
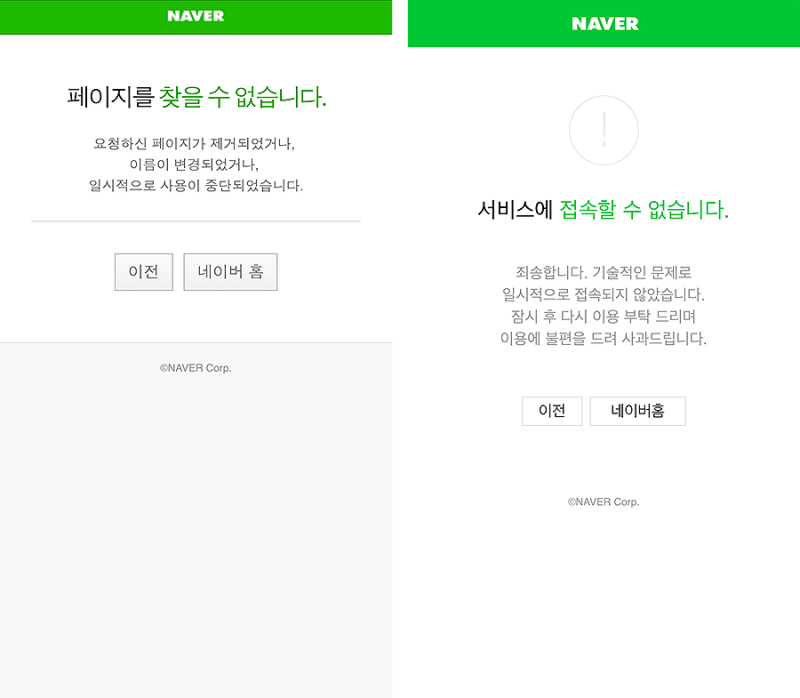
[ 초록창 모바일 화면 404 에러 문구 ]
이 밖에도 401, 403 에러 등이 나온다면 접근 권한이 없거나 금지하는 것이기 때문에 반복적인 행동을 하지 않도록 주의합시다.

[ 받아라 이것이 나의 함정카드다…! ]
robots.txt를 통해 접근범위가 어디까지 가능한지 확인해야합니다.
크롤러를 보통 봇(bot)이라고 부르는데 봇을 탐지하는 코드는 생각보다 많이 있습니다.(한번 찾아보세요!)
구글 및 네이버(등의 기타 브라우저)에서는 크롤링을 할 때 거의 대부분은 봇의 활동을 못하도록 해두었습니다. 어떤 일부 브라우저는 몇 가지 규칙을 만들어 가이드를 지킨다면 어느정도 활용할 수 있도록 허락해주기도 합니다.
대표적으로 “Robots.txt”를 활용하는 방법이 있습니다.
보통 홈페이지의 중요한 특정 부분을 가져가지 못하게 할 때 robots.txt 파일을 생성하고 파일을 서버 루트에 두면 봇이 접근할 수 없게 됩니다.

[ Google 검색센터 : robots.txt 가이드 일부분 ]
주소창에 “내가 확인하고 싶은 페이지/robots.txt”를 입력하고 Enter key를 누르면 아래와 같이 robots.txt 파일을 다운받아서 내용을 확인할 수 있습니다.


[ robots.txt 파일 다운로드 및 확인 ]
정적크롤링과 동적크롤링
아래는 대표적으로 사용되는 파이썬 크롤링 라이브러리 입니다.

[beautifulsoup logo]

[selenium logo]
이제 정적크롤링과 동적크롤링에 대해서 알아봅시다.
“정적크롤링”
한 페이지 내에서 원하는 정보가 전부 드러나는 정적인 데이터를 크롤링하여 가져오는 것
동적크롤링은 다음과 같습니다.
“동적크롤링”
여러 페이지를 이동하며 마우스로 클릭하거나 타이핑을 통한 입력으로 확인할 수 있는 데이터를 가져오는 것
몇년 전부터 동적인 페이지 제작이 유행을 타게 되면서 동적 크롤링을 많이 사용하는 추세입니다. 정적 페이지와 동적페이지의 구분 방법은 URL 주소창을 확인하는 방법입니다.
마우스 휠로 스크롤을 올리거나 내리면서 URL 주소창을 확인해보았을 때 URL 주소는 변화가 없고 페이지에 내용이 생성되면 동적 페이지입니다. 또한 동적인 페이지는 URL로만 접근을 할 수 없는 것을 말합니다.
정적 크롤링 vs 동적크롤링
대표적으로 다음과 같은 특징이 있습니다.
정적크롤링동적크롤링
| 라이브러리 | requests / urllib / beautifulsoup | chromedriver / Selenium |
| 속도 | 직관적으로 빠름 | 느림 |
| 비고 | 수집한 텍스트 데이터를 직관적으로 빠르게 확인 가능 | 실제로 동작하는 과정(클릭, 입력 등) 확인을 통해 디버깅하기 좋음 |
마무리
파이썬의 장점으로 몇줄 안되는 코드로 쉽게 웹을 스크랩핑 할 수 있습니다.
크롤링은 실제 데이터셋을 만들고 정제하는 과정에서 많이 사용되는 스킬이므로 유용하게 사용될 수 있으며 필자는 동적크롤링을 배워서 유용하게 사용했던 경험이 있습니다. 정적크롤링과 동적크롤링을 동시에 활용할 수 있다면 멋진 결과물을 얻으실 수 있습니다.
'IT > 보안' 카테고리의 다른 글
| 빠른 시작: 이메일 통신 서비스에 사용자 지정 확인된 도메인을 추가하는 방법 (0) | 2023.11.11 |
|---|---|
| 스푸핑을 방지할 수 있도록 SPF 설정 (0) | 2023.11.11 |
| DMARC 레코드에 대해 알려주세요. (0) | 2023.08.26 |
| DKIM 태그란 무엇인가요? (0) | 2023.08.26 |
| SPF 레코드에 대해 알려주세요. (1) | 2023.08.26 |